Crawl
Capture all URLs of a store.- ID
- URL
- Name
- Images
- Price
- Vendor
$0.2
/100 listings
Live, structured data for any product on the open web.
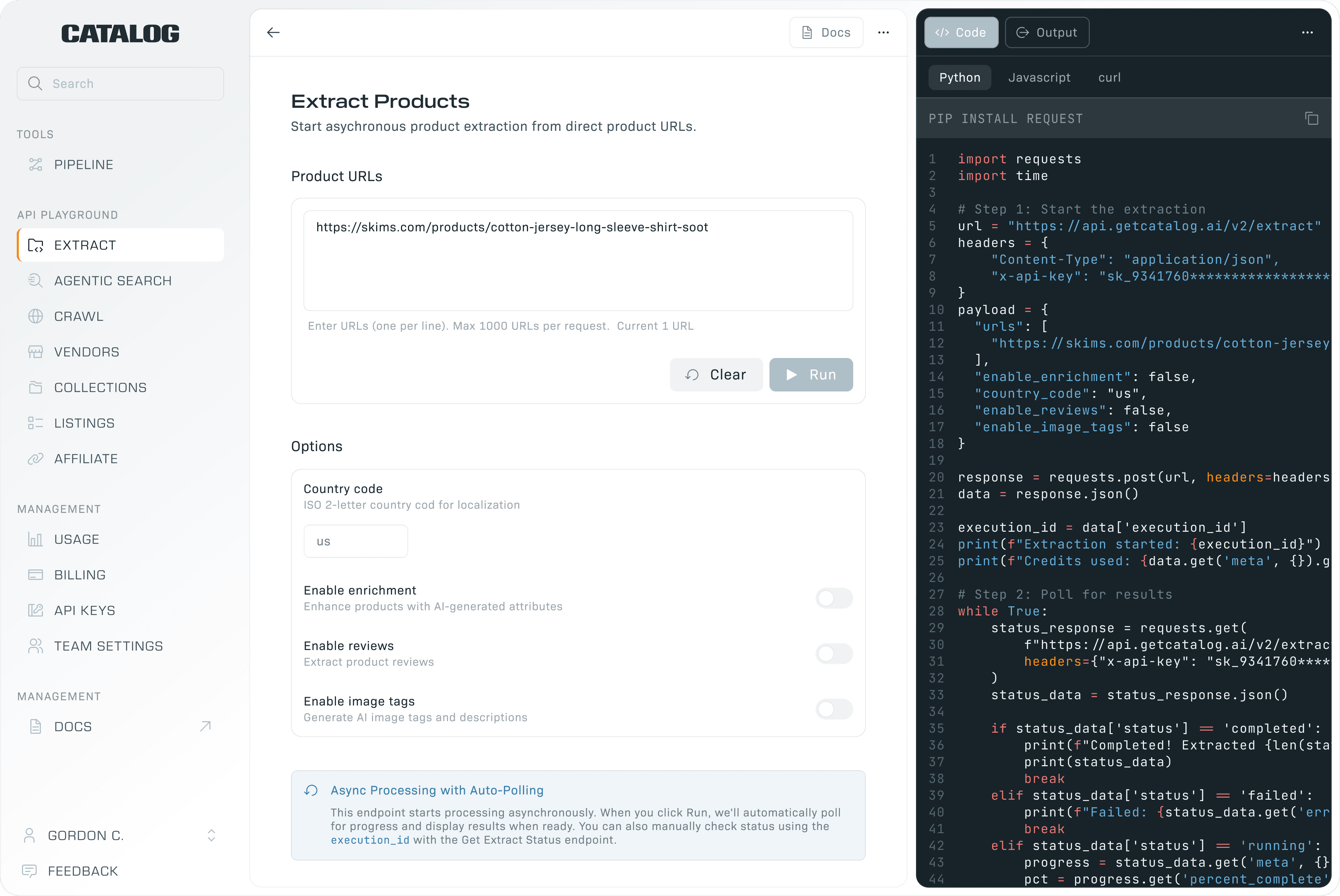
Drop a URL or a domain — Shopify, Amazon, custom builds, raw HTML. Get back the same 86+ normalized fields. No scrapers to maintain.
Six kinds of builders. One set of primitives. Built for the systems that transact — not the demos.
Ground every answer in real products, prices, and stock — not a model's best guess.
Index the open commerce web instead of a single feed. Stable IDs make embeddings and rerankers worth maintaining.
Pull live inventory and price before serving. Stop recommending what isn't in stock.
Variant-level parity across merchants. Match SKUs with consistent attributes and units.
Real-time assortments and monetizable outbound links. Affiliate commissions where supported, opt-in per request.
Reproducible product objects with timestamped freshness. Useful ground truth for benchmarking agents.
Five common paths to product data — and the trade each one quietly asks you to keep paying. We built Catalog so you stop paying it.
Break on every redesign. Return HTML.
We absorb the bot defenses, retries, and schema drift. You get typed objects.
Partial coverage. Missing the depth AI needs.
Any merchant on the open web, live, with the depth agents require.
Links and snippets. No variants or specs.
Full product objects. Variant-level price and stock. Normalized specs.
Built for links, not data.
Product-first. Affiliate is an option, not the model.
Months to build. Maintenance forever.
One integration. Your team works on the product.
Modular, per-listing pricing. No minimums. Volume discounts kick in automatically.
Per-call pricing. No commitments.
Flexible extraction depth per product URL.
Any e-commerce site on the open web. No partner agreements, no merchant onboarding, no gated coverage.
